SARIMAX:モデル選択、欠損データ¶
この例は、ARMAモデルを適合させるためのBox-Jenkins手法の適用において、DurbinとKoopman(2012年)の8.4章を反映しています。新しい機能として、欠損値のあるデータセットでも動作するモデルの能力があります。
[1]:
%matplotlib inline
[2]:
import numpy as np
import pandas as pd
from scipy.stats import norm
import statsmodels.api as sm
import matplotlib.pyplot as plt
[3]:
import requests
from io import BytesIO
from zipfile import ZipFile
# Download the dataset
df = pd.read_table(
"https://raw.githubusercontent.com/jrnold/ssmodels-in-stan/master/StanStateSpace/data-raw/DK-data/internet.dat",
skiprows=1, header=None, sep='\s+', engine='python',
names=['internet','dinternet']
)
モデル選択¶
DurbinとKoopmanと同様に、いくつかの値を欠損値として強制的に設定します。
[4]:
# Get the basic series
dta_full = df.dinternet[1:].values
dta_miss = dta_full.copy()
# Remove datapoints
missing = np.r_[6,16,26,36,46,56,66,72,73,74,75,76,86,96]-1
dta_miss[missing] = np.nan
その後、赤池情報量基準(AIC)を使用してモデル選択を検討できますが、各バリアントでモデルを実行し、AIC値が最も低いモデルを選択します。
ここで注意すべき点がいくつかあります。
特に自己回帰次数と移動平均次数が大きくなると、このような多数のモデルを実行する場合、最尤推定の収束が悪い可能性があります。この例は説明的なものであるため、以下では警告を無視します。
enforce_invertibility=Falseオプションを使用します。これにより、移動平均多項式を非可逆にすることができ、より多くのモデルを推定できます。いくつかのモデルは良好な結果を生成せず、AIC値はNaNに設定されます。DurbinとKoopmanが指摘しているように、高次モデルでは数値的な問題が発生するため、これは驚くべきことではありません。
[5]:
import warnings
aic_full = pd.DataFrame(np.zeros((6,6), dtype=float))
aic_miss = pd.DataFrame(np.zeros((6,6), dtype=float))
warnings.simplefilter('ignore')
# Iterate over all ARMA(p,q) models with p,q in [0,6]
for p in range(6):
for q in range(6):
if p == 0 and q == 0:
continue
# Estimate the model with no missing datapoints
mod = sm.tsa.statespace.SARIMAX(dta_full, order=(p,0,q), enforce_invertibility=False)
try:
res = mod.fit(disp=False)
aic_full.iloc[p,q] = res.aic
except:
aic_full.iloc[p,q] = np.nan
# Estimate the model with missing datapoints
mod = sm.tsa.statespace.SARIMAX(dta_miss, order=(p,0,q), enforce_invertibility=False)
try:
res = mod.fit(disp=False)
aic_miss.iloc[p,q] = res.aic
except:
aic_miss.iloc[p,q] = np.nan
完全な(欠損のない)データセットで推定されたモデルでは、AICはARMA(1,1)またはARMA(3,0)を選択します。DurbinとKoopmanは、簡潔さのためにARMA(1,1)の仕様の方が優れていると示唆しています。
欠損データセットで推定されたモデルでは、AICはARMA(1,1)を選択します。
**注記**:AIC値はDurbinとKoopmanとは異なる方法で計算されますが、全体的な傾向は似ています。
推定後分析¶
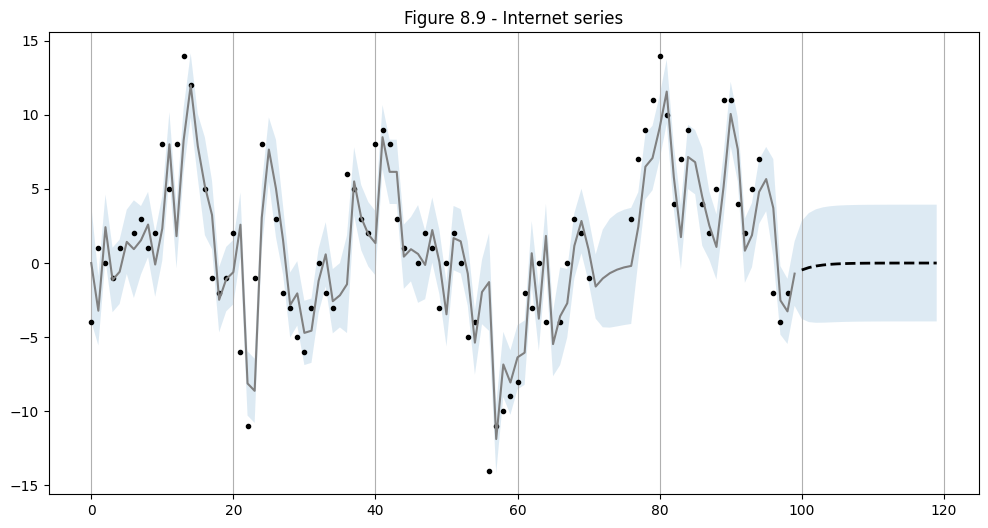
上記で選択したARMA(1,1)の仕様を使用して、標本内予測と標本外予測を実行します。
[6]:
# Statespace
mod = sm.tsa.statespace.SARIMAX(dta_miss, order=(1,0,1))
res = mod.fit(disp=False)
print(res.summary())
SARIMAX Results
==============================================================================
Dep. Variable: y No. Observations: 99
Model: SARIMAX(1, 0, 1) Log Likelihood -225.770
Date: Thu, 03 Oct 2024 AIC 457.541
Time: 15:50:00 BIC 465.326
Sample: 0 HQIC 460.691
- 99
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.6562 0.092 7.125 0.000 0.476 0.837
ma.L1 0.4878 0.111 4.390 0.000 0.270 0.706
sigma2 10.3402 1.569 6.591 0.000 7.265 13.415
===================================================================================
Ljung-Box (L1) (Q): 0.00 Jarque-Bera (JB): 1.87
Prob(Q): 0.96 Prob(JB): 0.39
Heteroskedasticity (H): 0.59 Skew: -0.10
Prob(H) (two-sided): 0.13 Kurtosis: 3.64
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
[7]:
# In-sample one-step-ahead predictions, and out-of-sample forecasts
nforecast = 20
predict = res.get_prediction(end=mod.nobs + nforecast)
idx = np.arange(len(predict.predicted_mean))
predict_ci = predict.conf_int(alpha=0.5)
# Graph
fig, ax = plt.subplots(figsize=(12,6))
ax.xaxis.grid()
ax.plot(dta_miss, 'k.')
# Plot
ax.plot(idx[:-nforecast], predict.predicted_mean[:-nforecast], 'gray')
ax.plot(idx[-nforecast:], predict.predicted_mean[-nforecast:], 'k--', linestyle='--', linewidth=2)
ax.fill_between(idx, predict_ci[:, 0], predict_ci[:, 1], alpha=0.15)
ax.set(title='Figure 8.9 - Internet series');